The principal tools driving automation, algorithms and machines, shape our lives in progressively varied and profound ways. But do these systems and programs treat us fairly? Should we believe them to be impartial because they haven’t fallen in love or been frustrated to the point of tears?
Jessie Smith, a PhD student in Information Sciences at CU Boulder points out that “people assume that because it’s data and algorithms, there isn’t bias. In reality, these mechanisms are only as objective as the programmer who created them.”
The term “bias” indicates a difference in an algorithms output relative to expected (statistically predicted) outcomes. These discrepancies can lead to inequitable treatment of users of a technology, but what does fair treatment mean in the first place? How should developers assess and communicate the impact of bias on their creations? Smith’s research thus far aims for answers to these questions.
Smith studies multi-stakeholder recommender systems: think of the “customers who viewed X also looked at Y” guidance, or product links that take up virtual real estate on many websites like Amazon or Netflix. In interviews, she asked users “what their ideas of fair treatment in recommendation might be, and why.” The responses will “inform the design of fairer and more transparent recommendation algorithms” to satisfy both the providers and consumers of products in machine-learning enhanced marketplaces.
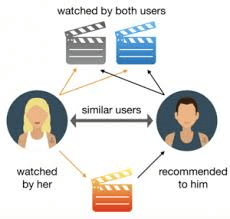
Netflix uses multi-stakeholder recommender systems to organize its content
Embedded in the interview responses were competing desires for diversity versus personalization of options. Participants “tended to trust nonprofits fairness goals more than for-profit companies,” and “described differences in terms of both motives and consequences” for these companies to promote fairness. Smith also identified cases where a company’s explicit explanation of provider-fairness in their algorithms can erode, rather than foster, trust.
We may be thinking along the same lines: how did Jessie take a plethora of opinions, and distill out the quantitative factors that can be fed into a learning machine or decision-making algorithm? Smith describes her study of recommender systems as a starting point for “analyzing what might cause discrepancies or changes between user’s opinions towards fairness” and part of a growing trend to investigate the intersection of learning algorithms and ethics.
Smith has been interested in the role ethics plays in algorithm development since an undergraduate project, where she scraped Web data to determine the answer to her question: “am I the same outward-facing person that I am on the inside?” Could an algorithm take in a smattering of likes, shares, pictures, comments, and create a virtual environment that accurately catered to who Smith thought she was? Could algorithms fulfill her needs as well as any other user? Just as in the case of recommender systems, powerful institutions like social media, the criminal justice and education systems, and increasingly pervasive technologies in healthcare depend on algorithms to make assessments under the scrutiny of these questions.
The effectiveness and impartiality of an algorithm’s outputs can have broad impacts on how a person is treated, what opportunities they are exposed to, and how well a person can adopt a technology. In recommender systems tailored towards maximum personalization, there could be an “increase in consumer biases (e.g. implicit bias in lending selection)”. On the other hand, “users expect some level of personalization to derive utility from the platform.”
Beyond effects of algorithmic bias, Smith is also eyeing the causes of algorithmic bias such as training data selection and developer bias. Just like us humans, algorithms are what they eat. If data scientists and engineers fail to think through how they curate the datasets that are fed to their learning machines, there are real consequences in the decisions those systems will make down the line.

Credit: xkcd
Similarly (competence in scientific abilities notwithstanding) if developers of certain genders, colors, and value systems dominate a team, there can be unintended blind spots or statistical correlations mistaken for causations embedded into that team’s code. Inclusivity and equal representation have been issues for society across the centuries, and in the era of machine learning they are also present.
Within the last year Smith has turned into a legitimate science communicator, hosting projects like “The Radical AI podcast”, the “SciFi_IRL” Youtube channel, and regularly speaks at conferences and workshops on the issues of ethical algorithm development. Her responsibilities as a graduate student notwithstanding, Jessie believes it crucial to foster discussion on “how we can/should/should not encode philosophical and social issues” into the algorithm and machine learning development processes.
These issues didn’t receive light of day while Smith pursued her undergraduate studies, and the experience appears to be the rule rather than the exception. To address this, she is working with CU’s Casey Fiesler to incorporate ethics into the technical education of coding by framing homework and projects around “problems that are deeply rooted in complex social systems”. When students see how their algorithms might treat humans without equity at an early stage, a seed of perspective beyond “did it work?” begins to bloom.
Humanity’s proclivity to create tools is arguably the defining factor between our species and all others. Machine learning represents a new frontier in tool-making, but the tools not only allow humans to change the world, the tools also change humans themselves.
When considering pervasiveness and impact, machine learning algorithms are taking their place in history alongside tools like the Internet, the steam combustion engine, and the abacus. To ensure they are implemented effectively, fairly, and with a nuanced understanding of their impacts, Smith invites us to consider their ethics.
By Adrian Unkeles
